ChatGLM-6B 由清华大学唐杰团队开发的是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
在我笔记本单卡2060(6G)上可以加载模型,但推理时候会报cuda错误,可能是笔记本上显卡功率跟不上,性能发挥不出最佳状态。之后换成2080ti、3090ti都可以轻松运行。没有GPU的情况下也可以使用CPU,但推理非常慢,本人使用自己笔记本电脑CPU进行加载,推理过了十几分钟还没有得到回复,不过能在消费级显卡上运行起来已经为大模型部署降低了很大的门槛了。
因此推断,笔记本上2070以上的显卡、台式机2060以上显卡可以运行ChatGLM-6B。可根据显卡性能不同,设置以不同量化精度加载模型。不同量化精度对应的推理需要的最小显存如下:
| 量化等级 | 最低GPU显存 | 量化代码 |
| FP16(无量化) | 13 GB | model.half().cuda() |
| INT8 | 10 GB | model.half().quantize(8).cuda() |
| INT4 | 6 GB | model.half().quantize(4).cuda() |
| -- | CPU | model.float() |
ChatGLM-6B 项目提供了两种对话入口,一种图形界面方式,一种命令行方式:
图形界面方式:
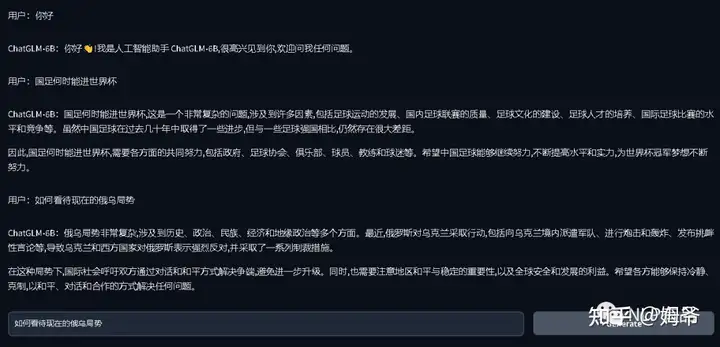
命令行方式:
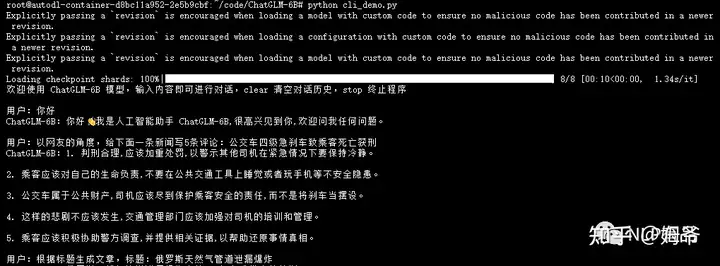
使用了几次后,感觉还挺好,在性能和回复的流畅度、效果上都是很可以接受的,毕竟相对于GPT3、GPT4上千亿/万亿的参数来说,在60亿参数,并且NLP平民能消费的起情况下,可以说是很Niubility了。
但愿,大模型方向会在ChatGLM-6B的引领下,向着小而精的方向发展,这样,我们NLP平民才能搭上这班车,不至于掉队。
