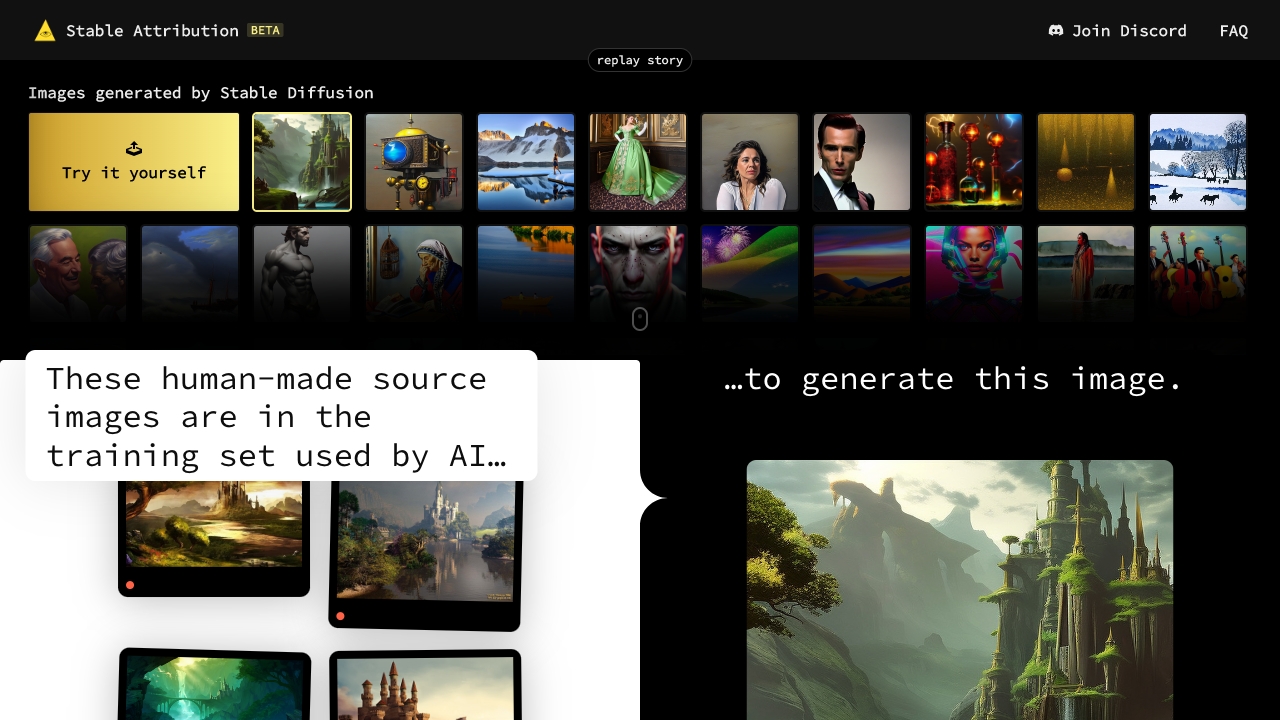
When an A.I. model is trained to create images from text, it uses a huge dataset of images and their corresponding captions. The model is trained by showing it the captions, and having it try to recreate the images associated with each one, as closely as possible. The model learns both general concepts present in millions of images, like what humans look like, as well as more specific details like textures, environments, poses and compositions which are more uniquely identifiable.
世界ランキング
#5,992,415 2,276,681
国家ランキング
355,903 84,897
カテゴリレベル
11,074 1,783
アクセス
6.9K
リバウンド率
51.84%
アクセスごとのページ数
0.78
平均受診時間
00:00:33
アクセス 4.68K 価格設定モデル
アクセス 0 価格設定モデル
アクセス 114.74M 価格設定モデル